Data Lake: Definición, Beneficios y Características
¿Qué es un data lake?
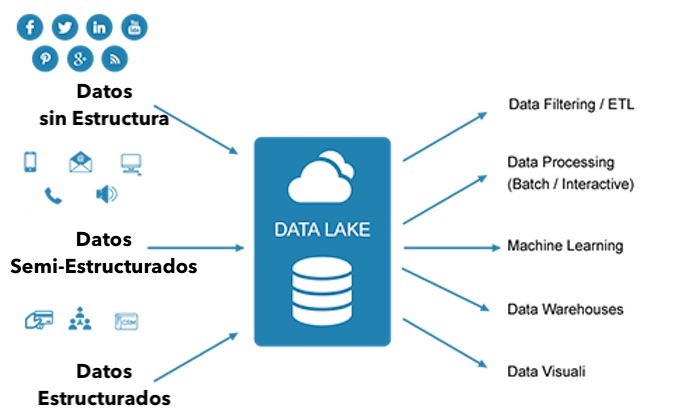
Un data lake es un repositorio centralizado que le permite almacenar todos sus datos estructurados y no estructurados en cualquier escala. Puede almacenar sus datos tal como están, sin tener que estructurar primero los datos, y ejecutar diferentes tipos de análisis, desde paneles y visualizaciones hasta procesamiento de big data, análisis en tiempo real y aprendizaje automático para guiar mejores decisiones.
Un data lake es una ubicación central en la que almacenar todos sus datos, independientemente de su fuente o formato. Normalmente, aunque no siempre, se crea utilizando Hadoop. Los datos pueden ser estructurados o no estructurados. A continuación, puede utilizar una variedad de herramientas de almacenamiento y procesamiento, generalmente herramientas en el ecosistema extendido de Hadoop, para extraer valor rápidamente e informar decisiones clave de la organización.
Debido a la creciente variedad y volumen de datos, los data lake son un enfoque arquitectónico emergente y poderoso, especialmente a medida que las empresas recurren a aplicaciones móviles basadas en la nube e Internet of Things (IoT) como medios de entrega en tiempo adecuado para big data.
Data Lake versus Data Warehouse
Las diferencias entre los almacenes de datos empresariales (Data Warehouse o EDW) y los lagos de datos son importantes. Una EDW se alimenta de datos de una amplia variedad de aplicaciones empresariales. Naturalmente, los datos de cada aplicación tienen su propio esquema, que requiere que los datos se transformen para que se ajusten al propio esquema predefinido de EDW.
Diseñado para recopilar solo datos que se controlan por calidad y que se ajustan a un modelo de datos de la empresa, el EDW es capaz de responder solo a un número limitado de preguntas.
| Características | Almacén de datos | Data Lake |
|---|---|---|
| Datos | Relacional de sistemas transaccionales, bases de datos operacionales y aplicaciones de línea de negocios | No relacional y relacional de dispositivos IoT, sitios web, aplicaciones móviles, redes sociales y aplicaciones corporativas |
| Esquema | Diseñado antes de la implementación de DW (esquema en escritura) | Escrito en el momento del análisis (schema-on-read) |
| Precio / rendimiento | Resultados de consulta más rápidos con un mayor costo de almacenamiento | Los resultados de las consultas se vuelven más rápidos usando almacenamiento de bajo costo |
| Calidad de datos | Datos altamente curados que sirven como la versión central de los reales | Cualquier información que pueda o no ser curada (es decir, datos sin procesar) |
| Usuarios | Analistas comerciales | Científicos de datos, desarrolladores de datos y analistas de negocios (usando datos curados) |
| Analítica | Informe por lotes, BI y visualizaciones | Aprendizaje automático, análisis predictivo, descubrimiento de datos y creación de perfiles |
Los lagos de datos, por otro lado, reciben información en su forma nativa. Poco o ningún procesamiento se lleva a cabo para adaptar la estructura a un esquema empresarial.
Ventajas y beneficios de un Data Lake
La mayor ventaja de los lagos de datos es la flexibilidad.
Al permitir que los datos permanezcan en su formato nativo, hay disponible un flujo de datos mucho mayor y más oportuno para el análisis.
Algunos de los beneficios de un data lake incluyen:
- Capacidad de obtener valor a partir de tipos ilimitados de datos
- Posibilidad de almacenar todo tipo de datos estructurados y no estructurados en un data lake, desde datos de CRM hasta publicaciones en redes sociales
- Mayor flexibilidad: no tiene que tener todas las respuestas por adelantado
- Posibilidad de almacenar datos en bruto: puede refinarlo a medida que su comprensión mejore
- Formas ilimitadas de consultar los datos
- Aplicación de una variedad de herramientas para obtener una idea de lo que significan los datos
- Eliminación de silos de datos
- Acceso democratizado a los datos a través de una única vista unificada de datos en toda la organización cuando se utiliza una plataforma de gestión de datos efectiva
Características de un data lake
Para ser clasificado como un data lake, un repositorio de datos grandes debe exhibir tres características clave:
-
Un único repositorio compartido de datos, normalmente almacenado en el Sistema de archivos distribuido (DFS). Los lagos de datos de Hadoop conservan los datos en su forma original y capturan los cambios a los datos y la semántica contextual a lo largo del ciclo de vida de los datos.Este enfoque es especialmente útil para las actividades de cumplimiento y auditoría interna.
Esta es una mejora con respecto al EDW tradicional, donde si los datos han sufrido transformaciones, agregaciones y actualizaciones, es difícil juntar datos cuando es necesario, y las organizaciones tienen dificultades para determinar la procedencia de los datos.
-
Incluye funcionalidades de orquestación y programación de trabajos (por ejemplo, a través de YARN). La ejecución de la carga de trabajo es un requisito previo para Hadoop empresarial.
YARN proporciona administración de recursos y una plataforma central para entregar herramientas consistentes de operaciones, seguridad y control de datos en los clústeres de Hadoop, asegurando que los flujos de trabajo analíticos tengan acceso a los datos y la potencia informática que requieren.
-
Contiene un conjunto de aplicaciones o flujos de trabajo para consumir, procesar o actuar sobre los datos.
El fácil acceso de los usuarios es una de las características de un data lake, debido a que las organizaciones conservan los datos en su forma original. Ya sea estructurado, no estructurado o semiestructurado, los datos se cargan y almacenan tal cual. Los propietarios de datos pueden entonces consolidar datos de clientes, proveedores y operaciones, eliminando barreras técnicas e incluso políticas para compartir datos.
Los data lake son cada vez más importantes para las estrategias de datos empresariales. Los datos de los lagos responden mejor a las realidades de los datos actuales: volúmenes y variedades de datos mucho mayores, mayores expectativas de los usuarios y la rápida globalización de las economías.