Bases de Datos Distribuidas: Popularidad, Uso y Tipos
Las bases de datos distribuidas ofrecen algunas ventajas clave sobre las bases de datos centralizadas. Muchas empresas están cambiando a bases de datos distribuidas (en las cuales la base de datos, como su nombre lo indica, se distribuye a través de una matriz de servidores en varias ubicaciones), por una variedad de razones.
Veamos algunas de las ventajas básicas de las bases de datos distribuidas, un escenario típico en el que se usan y los diferentes formatos en los que se distribuyen los datos a través del sistema de datos distribuidos.
Qué son las bases de datos distribuidas y los datos distribuidos
Una base de datos distribuida es una colección de múltiples bases de datos interconectadas, que se extienden físicamente a través de varias ubicaciones que se comunican a través de una red informática.
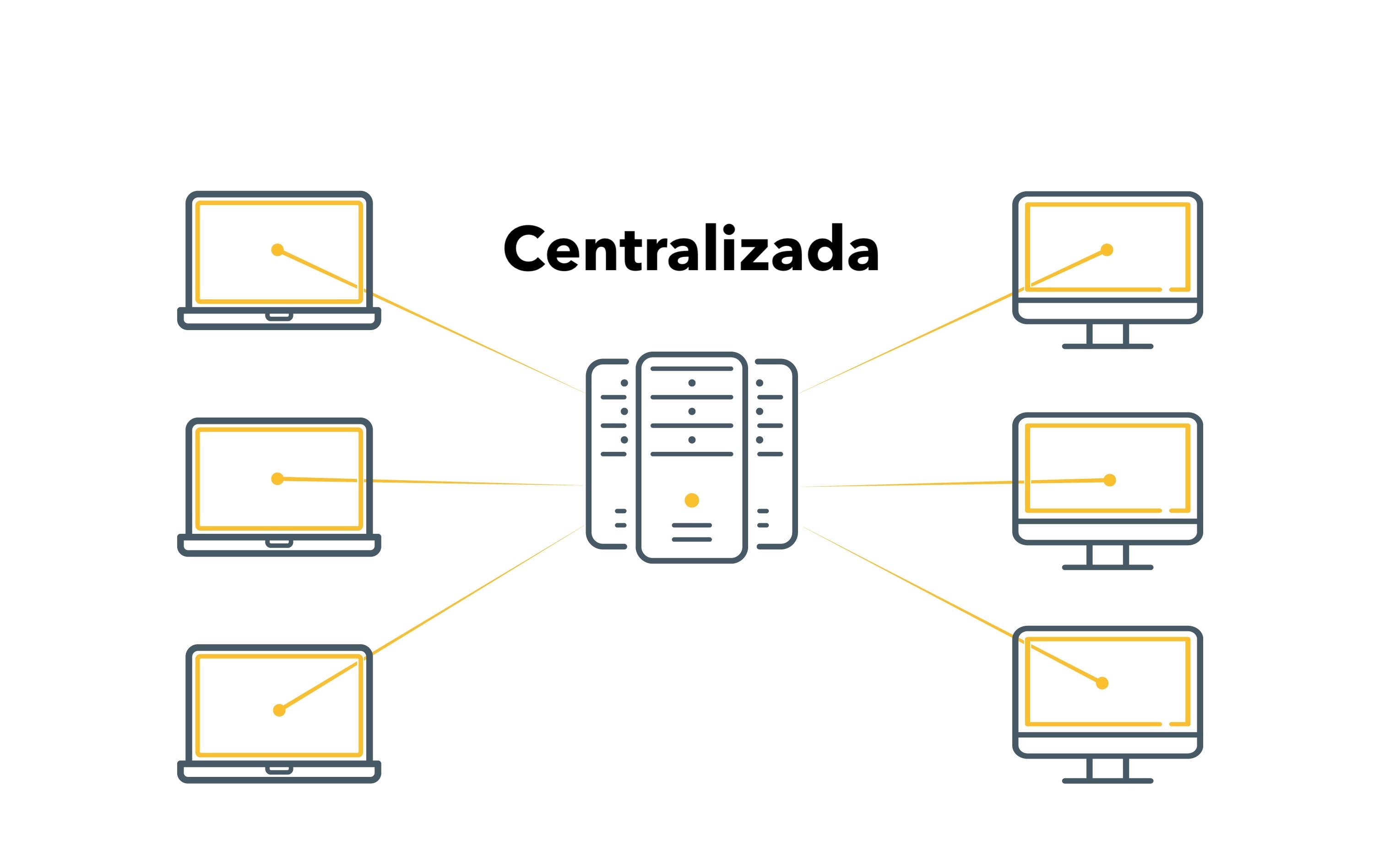
Base de datos Centralizada
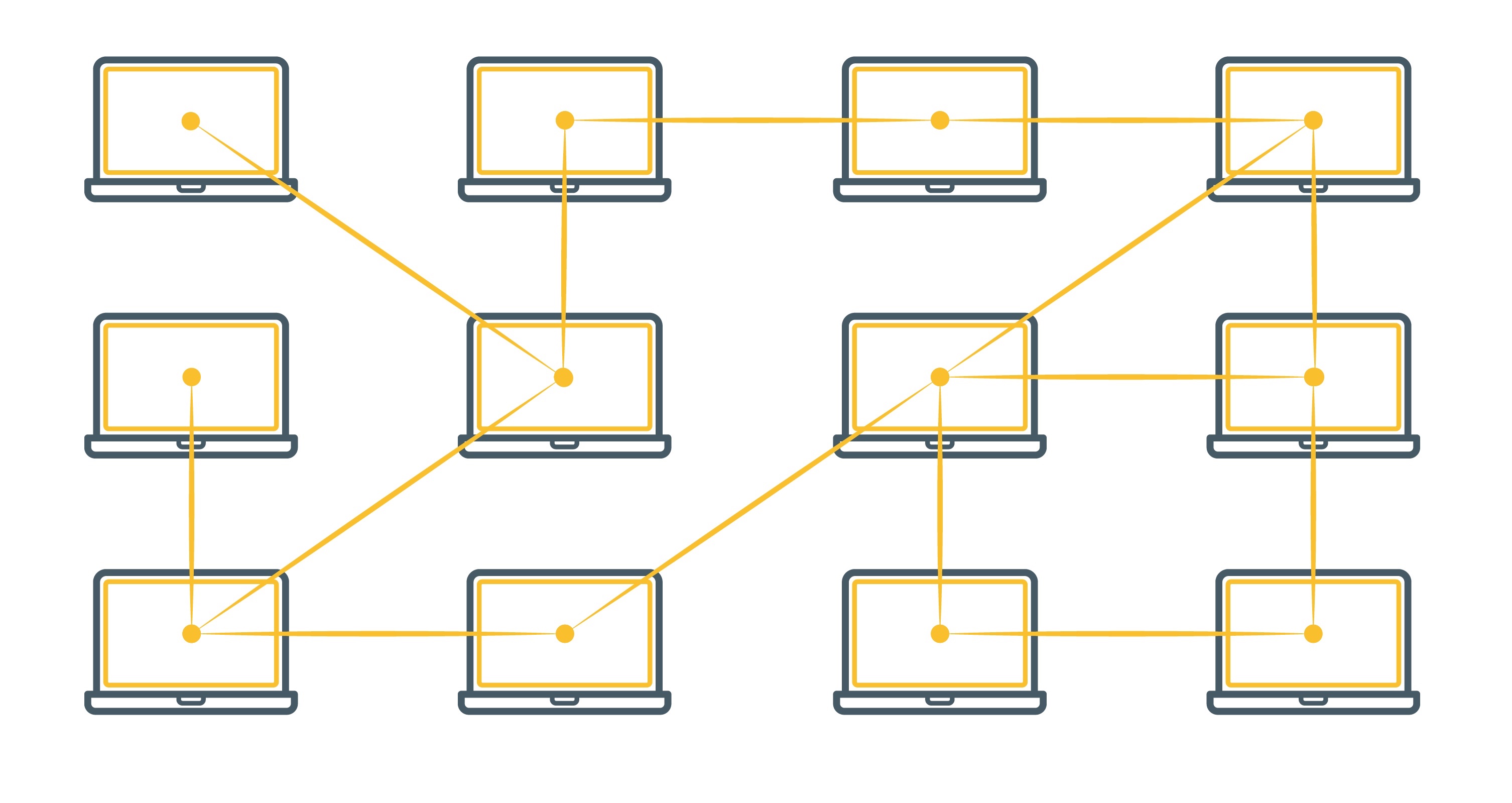
Base de datos Descentralizada
Sistema de gestión de bases de datos distribuidas
Un sistema de administración de bases de datos distribuidas (DDBMS) es un sistema de software centralizado que administra una base de datos distribuida de una manera como si estuviera almacenada en una sola ubicación.
Caracteristicas
- Se usa para crear, recuperar, actualizar y eliminar bases de datos distribuidas.
- Sincroniza la base de datos periódicamente y proporciona mecanismos de acceso en virtud de los cuales la distribución se vuelve transparente para los usuarios.
- Asegura que los datos modificados en cualquier sitio se actualicen universalmente.
- Se utiliza en áreas de aplicación donde numerosos usuarios procesan y acceden grandes volúmenes de datos simultáneamente.
- Está diseñado para plataformas de bases de datos heterogéneas.
- Mantiene la confidencialidad y la integridad de los datos de las bases de datos.
Por qué las bases de datos distribuidas son populares
Aquí están las razones básicas por las cuales muchas organizaciones están dejando el modelo centralizado a favor de la distribución de bases de datos:
Fiabilidad: crear una infraestructura es similar a invertir: diversifíquese para reducir sus posibilidades de pérdida. Específicamente, si ocurre una falla en un área de la distribución, toda la base de datos no experimenta un retroceso.
Seguridad: puede otorgar permisos a secciones individuales de la base de datos general, para una mejor protección interna y externa.
Rentable: los precios del ancho de banda disminuyen porque los usuarios acceden a datos remotos con menos frecuencia.
Acceso local: al igual que en el punto 1 anterior, si hay una falla en la red general, aún puede obtener acceso a su parte de la base de datos.
Crecimiento: si agrega una nueva ubicación a su negocio, es simple crear un nodo adicional dentro de la base de datos, lo que hace que la distribución sea altamente escalable.
Velocidad y eficiencia de los recursos: la mayoría de las solicitudes y otras formas de interactividad con la base de datos se realizan a nivel local, lo que también reduce el tráfico remoto.
Responsabilidad y contención: debido a que fallas técnicas o fallas ocurren localmente, el problema está contenido y puede ser manejado por el personal de TI designado para manejar esa parte de la empresa.
¿Quién usa bases de datos distribuidas?
Las organizaciones que tienen numerosas oficinas en distintas ubicaciones geográficas suelen utilizar bases de datos distribuidas.
Normalmente, una sucursal individual interactúa principalmente con los datos que pertenecen a sus propias operaciones, con una necesidad mucho menos frecuente de datos generales de la empresa.
Existe una necesidad incoherente de cualquier información central de las sucursales en ese caso. Sin embargo, la oficina central de la empresa todavía debe tener un flujo constante de información desde cada ubicación.
Para resolver ese problema, una base de datos distribuida generalmente opera al permitiendo que cada ubicación de la empresa interactúe directamente con su propia base de datos durante las horas de trabajo. Durante las horas no pico, cada día, toda la base de datos recibe un lote de datos de cada rama.
Tipos de datos distribuidos
Los datos distribuidos se pueden dividir en cinco tipos básicos, como se detalla a continuación:
Datos duplicados: la replicación de datos se usa para crear instancias adicionales de datos en diferentes partes de la base de datos. Usando esta táctica, una base de datos distribuida puede evitar el tráfico excesivo porque se puede acceder a los datos idénticos localmente.
En este tipo de sistema de datos distribuidos, las actualizaciones pueden configurarse según la importancia de que la base de datos tenga los detalles correctos momento a momento (o durante cualquier período de tiempo). Tenga en cuenta que la replicación es especialmente valiosa cuando no necesita revisiones para que aparezcan en todo el sistema de datos distribuidos en tiempo real.
Este tipo de datos facilita el suministro de datos desde cualquier sección a cualquier otra sección de la base de datos más grande si los datos de la última sección se ven comprometidos por cualquier tipo de error. Tenga en cuenta, sin embargo, que con la replicación, pueden producirse colisiones.
Datos fragmentados horizontalmente: esta categoría de distribución de datos implica el uso de claves primarias (cada una de las cuales se refiere a un registro en la base de datos). La fragmentación horizontal se usa comúnmente para situaciones en las que ubicaciones específicas de una empresa generalmente solo necesitan acceso a la base de datos correspondiente a su rama específica.
Datos verticalmente fragmentados: con la fragmentación vertical, las claves primarias se utilizan nuevamente. Sin embargo, en este caso, las copias de la clave primaria están disponibles dentro de cada sección de la base de datos (accesible para cada rama). Este tipo de formato funciona bien para situaciones en las que una sucursal de una empresa y la ubicación central interactúan con las mismas cuentas, pero quizás de diferentes maneras (como cambios en la información de contacto del cliente frente a cambios en las cifras financieras).
Datos reorganizados: la reorganización significa que los datos se han ajustado de una manera u otra, como es típico en las bases de datos de soporte de decisión. En algunos casos, hay dos sistemas distintos que manejan las transacciones y el soporte de decisiones.
Si bien los sistemas de soporte de decisiones pueden ser más difíciles de mantener técnicamente, el procesamiento de transacciones en línea (OLTP) a menudo requiere una reconfiguración para permitir grandes cantidades de solicitudes.
Datos de esquema separado: esta categoría de datos divide la base de datos y el software utilizado para acceder a diferentes departamentos y situaciones, por ejemplo, datos de usuario frente a datos de productos. Por lo general, existe una superposición entre las diversas bases de datos dentro de este tipo de distribución.