
Almacenes de columnas anchas
Como para los almacenes valor-clave, los almacenes de columnas anchas tienen tablas que contienen columnas. La pequeña diferencia es que adoptan un enfoque híbrido que mezcla las características declarativas de las bases de datos relacionales con las de clave-valor.
Las bases de datos de columnas anchas almacenan tablas de datos como secciones de columnas de datos en lugar de filas de datos.
Funcionamiento
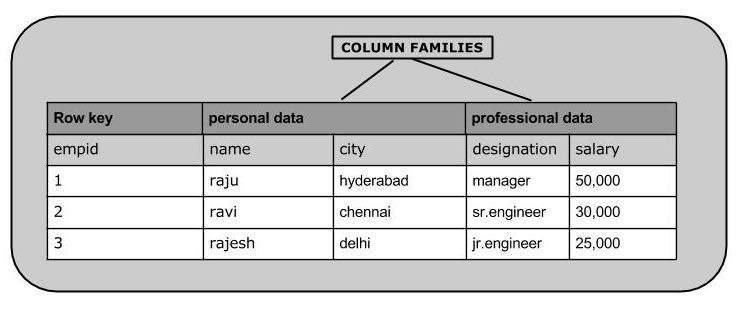
La forma en que funciona este híbrido, es declarando las llamadas familias de columnas como parte de un esquema confiable.
Pero las familias de columnas funcionan de alguna manera como categorías de columnas, y dentro de una familia de columnas podemos tener diferentes columnas en cada fila.
Las bases de datos de columnas anchas utilizan un vocabulario ligeramente diferente, llamando a las familias de columnas como "Super Columns" y llamando a las tablas como "Super Column Families". Los almacenes de columnas anchas pueden ser las bases de datos más fundamentales en los sitios de grandes empresas.
Big Table, que es propiedad de Google, tiende a usarla con su motor de cálculo MapReduce para trabajar con grandes conjuntos de datos.
Yahoo apoyó el mundo de código abierto y creó una versión de código abierto de MapReduce llamada Hadoop y una fuente abierta de Big Table llamada HBase.
Facebook presentó su propia base de datos llamada Cassandra, que también es una base de datos de columnas anchas.
Beneficios
Para datos razonablemente estructurados (incluso si esa estructura es algo variable entre diferentes entradas en la base de datos), las bases de datos de columna ancha tienen las siguientes ventajas sobre otros tipos de NoSQL:
- Altamente escalable, muy adecuado para la distribución en múltiples almacenes de datos y nodos informáticos.
- Ordenación y manipulación de datos, directamente desde la base de datos en lugar de depender únicamente de la aplicación.
- Indexación: algunas bases de datos indexan diferentes niveles de columnas para ayudar con el procesamiento de datos.
- Mayor granularidad: poder actualizar una columna individual en lugar de tener que reemplazar todos los datos cuando algo cambia.
Incluso para datos regulares y altamente estructurados (donde cada fila tiene la misma estructura de columnas) que se adaptan cómodamente a una base de datos relacional, las bases de datos de gran ancho tienen una ventaja en su capacidad de procesamiento y capacidad para trabajar con conjuntos de datos verdaderamente masivos.
Mientras que los sistemas a menudo se ralentizan a medida que se agregan más filas (los índices se vuelven más desordenados y menos útiles), la simplificación de NoSQL garantiza un rendimiento confiable.
Las dos bases de datos NoSQL de columna ancha más populares son Cassandra y HBase, y Facebook ha utilizado ambas para manejar la mensajería y la búsqueda en la bandeja de entrada, originalmente usando Cassandra pero luego cambiando.
Otros usuarios prominentes incluyen Netflix, Reddit, Twitter y Digg, todos ejemplos perfectamente aceptables de cómo las bases de datos de columnas amplias pueden ser adecuadas para sistemas con grandes cantidades de datos, y que son lo suficientemente estables y confiables para que las grandes empresas dependan de ellas.
Cassandra y HBase son soluciones de servidor de fuente abierta, y varias compañías ofrecen acceso a ellas a través de paquetes totalmente alojados para personas que no desean ejecutar su propio servidor de base de datos.
Otro sistema popular es el SimpleDB de Amazon y, como parte de sus servicios de computación en la nube, puede ser una forma barata (incluso gratuita para aplicaciones a pequeña escala) de investigar el uso de bases de datos de gran columna en proyectos.
Opciones
Sección NoSQL: