
Modelado de Datos: Pasos para modelar datos
- Modelado de Datos
- Tipos de Modelos de Datos
- Cómo modelar los datos
Para un desarrollador de aplicaciones, es fundamental conocer los fundamentos del modelado de datos para que no solo puedan leer modelos de datos sino también trabajar eficazmente con los administradoes de agile que son responsables de los aspectos orientados a los datos de su proyecto.
Las siguientes tareas de modelado de datos se realizan de forma iterativa:
- Identificar tipos de entidades
- Identificar atributos
- Aplicar convenciones de nomenclatura
- Identificar relaciones
- Aplicar modelos de modelos de datos
- Asignar claves
- Normalizar para reducir la redundancia de datos
- Desnormalizar para mejorar el rendimiento
Identificar tipos de entidades
Un tipo de entidad, también llamado simplemente entidad (no es exactamente una terminología precisa, pero muy común en la práctica), es similar conceptualmente al concepto de una clase de orientación a objetos: un tipo de entidad representa una colección de objetos similares.
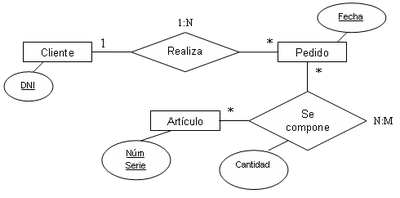
Un tipo de entidad podría representar una colección de personas, lugares, cosas, eventos o conceptos. Los ejemplos de entidades en un sistema de entrada de pedidos incluirían Cliente, Pedido, y Artículo.
La diferencia entre una clase y un tipo de entidad es que las clases tienen datos y comportamiento, mientras que los tipos de entidad solo tienen datos.
Idealmente, una entidad debería ser normal, y de cohesión en el modelado de datos. Una entidad normal representa un concepto, al igual que una clase cohesiva modela un concepto.
Por ejemplo, cliente y pedido son claramente dos conceptos diferentes, por lo tanto, tiene sentido modelarlos como entidades separadas.
Identificar atributos
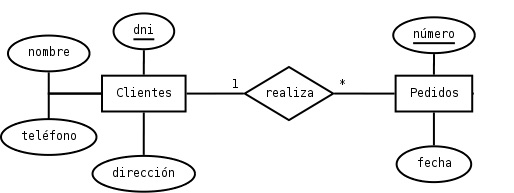
Cada tipo de entidad tendrá uno o más atributos de datos. Por ejemplo, en la Figura anterior se ve que Cliente tiene atributos como Nombre y Teléfono. Y en la tabla de entidades, las entidades tienen columnas de datos correspondientes a sus atributos (una columna es la implementación de un atributo de datos dentro de una base de datos relacional) .
Los atributos también deben ser coherentes desde el punto de vista de su dominio, algo que a menudo es una decisión. En el diagrama decidimos que queríamos modelar el hecho de que las personas tenían tanto Nombre y Teléfono (también pudo Nombre, Apellido y Teléfono).
Obtener el nivel de detalle correcto puede tener un impacto significativo en sus esfuerzos de desarrollo y mantenimiento. Refactorizar una sola columna de datos en varias columnas puede ser difícil, la refacturación de bases de datos se describe en detalle en refactorización de la base de datos, aunque especificar demasiado un atributo (por ejemplo, tener tres atributos para el código postal cuando sols necesita uno) puede generar una sobrecarga del sistema y, por lo tanto, incurrirá en mayores costos de desarrollo y mantenimiento de los que realmente necesita.
Aplicar convenciones de nomenclatura
Su organización debe tener estándares y pautas aplicables al modelado de datos, algo que debería poder obtener de los administradores de su empresa (si no existen, debe presionar para que se existan algunos).
Estas directrices deben incluir convenciones de nomenclatura para el modelado lógico y físico, las convenciones de nomenclatura lógica deben centrarse en la legibilidad humana, mientras que las convenciones de nomenclatura física reflejarán consideraciones técnicas.
Puede ver claramente que se aplicaron diferentes convenciones de nomenclatura en la figura Cliente-Pedido (1,*).
La idea básica es que los desarrolladores deben aceptar y seguir un conjunto común de estándares de modelado en un proyecto de software. Así como hay un valor en seguir las convenciones de codificación comunes, el código de limpieza que sigue las pautas de codificación elegidas es más fácil de comprender y evolucionar que el código que no lo hace, y existe un valor similar en las siguientes convenciones de modelado comunes.
Identificar relaciones
En el mundo real, las entidades tienen relaciones con otras entidades. Por ejemplo, los clientes realizan pedidos, los clientes viven en direcciones, y las líneas de pedido forman parte de los pedidos.
Realizar, vivir y formar parte de todos los términos que definen las relaciones entre las entidades.
Las relaciones entre entidades son conceptualmente idénticas a las relaciones (asociaciones) entre objetos.
En este artículo puedes ver los tipos de relaciones en bases de datos.
También es necesario identificar la cardinalidad y la facultad de una relación (el UML combina los conceptos de opcionalidad y cardinalidad en el concepto único de multiplicidad).
La cardinalidad representa el concepto de "cuántos", mientras que la opcionalidad representa el concepto de "si debe tener algo".
Por ejemplo, no es suficiente saber que los clientes hacen pedidos. ¿Cuántas órdenes puede colocar un cliente? ¿Ninguna, una o varias? Además, las relaciones son calles de doble sentido: los clientes no solo hacen pedidos, sino que los clientes los colocan.
Esto lleva a preguntas como: ¿cuántos clientes se pueden inscribir en un pedido dado y es posible tener un pedido sin clientes involucrados?
La Figura Cliente-Pedido muestra que los clientes colocan cero o más pedidos y que un pedido determinado es realizado por un cliente y un solo cliente.
Aunque el UML distingue entre diferentes tipos de relaciones (asociaciones, herencia, agregación, composición y dependencia), los modeladores de datos a menudo no están tan preocupados con este tema como lo están los modeladores de objetos.
La subtipificación, una aplicación de herencia, a menudo se encuentra en modelos de datos, un ejemplo de lo cual es la relación entre Cliente y sus dos tipos o "subentidades" como Cliente VIP y Cliente Regular.
La agregación y composición son mucho menos comunes y típicamente deben ser implícitas desde el modelo de datos, como puede ver con la función que el elemento de línea lleva con el pedido.
Las dependencias UML suelen ser una construcción de software y, por lo tanto, no aparecerían en un modelo de datos, a menos que fuera un modelo físico muy detallado que mostrara cómo las vistas, desencadenantes o procedimientos almacenados dependían de otros aspectos del esquema de la base de datos.
Aplicar patrones de modelo de datos
Algunos modeladores de datos aplicarán patrones de modelos de datos comunes, el modelo de datos de David Hay es la mejor referencia sobre el tema, así como los desarrolladores orientados a objetos aplicarán patrones de análisis (Fowler 1997, Ambler 1997) y patrones de diseño (Gamma et al., 1995).
Los patrones del modelo de datos son conceptualmente los más cercanos a los patrones de análisis porque describen soluciones para problemas de dominio común. Los modelos de Hay son una referencia muy buena para cualquier persona involucrada en el modelado de nivel de análisis, incluso cuando se toma un enfoque de objetos en lugar de un enfoque de datos porque sus patrones modelan estructuras comerciales de una amplia variedad de dominios comerciales.
Asignar llaves
Hay dos estrategias fundamentales para asignar claves a las tablas. En primer lugar, podría asignar una clave natural que sea uno o más atributos de datos existentes que sean exclusivos del concepto de negocio.
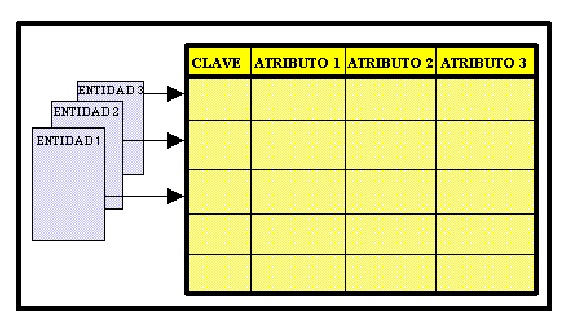
La tabla Cliente puede tener una claves candidatas, en este caso DNI o número de identificación nacional. En segundo lugar, podría introducir una nueva columna, llamada clave sustituta, que es una clave que no tiene ningún significado comercial.
Un ejemplo de esto es la columna Clave de la tabla de la tabla de entidades. Algunas entidades no tienen una clave natural "fácil", por lo tanto, la introducción de una clave sustituta es una opción mucho mejor en algunos casos.
Normalizar para reducir la redundancia de datos
La normalización de datos es un proceso en el que los atributos de los datos dentro de un modelo de datos se organizan para aumentar la cohesión de los tipos de entidades.
En otras palabras, el objetivo de la normalización de datos es reducir e incluso eliminar la redundancia de datos, una consideración importante para los desarrolladores de aplicaciones porque es increíblemente difícil almacenar objetos en una base de datos relacional que mantiene la misma información en varios lugares.
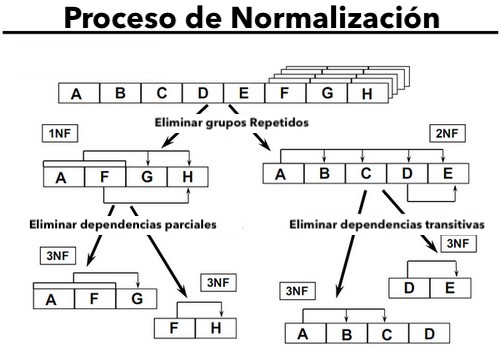
La figura resume las tres reglas de normalización más comunes que describen cómo poner los tipos de entidades en una serie de niveles crecientes de normalización.
Con respecto a la terminología, se considera que un esquema de datos está en el nivel de normalización de su tipo de entidad menos normalizada. Por ejemplo, si todos los tipos de entidad están en la segunda forma normal (2NF) o superior, entonces diremos que su esquema de datos está a 2NF.
Desnormalizar para mejorar el rendimiento
Los esquemas de datos normalizados, cuando se ponen en producción, a menudo sufren problemas de rendimiento. Esto tiene sentido: las reglas de normalización de datos se centran en reducir la redundancia de datos, no en mejorar el rendimiento del acceso a los datos.
Una parte importante del modelado de datos es desnormalizar partes de su esquema de datos para mejorar los tiempos de acceso a la base de datos.
El objetivo principal de el modelo es procesar nuevos pedidos de clientes en línea lo más rápido posible. Para hacer esto, los clientes deben poder buscar los artículos y agregarlos a su orden rápidamente, eliminar los artículos de su pedido si es necesario, y luego tener su pedido final totalizado y registrado rápidamente.
El objetivo secundario del sistema es procesar, enviar y facturar las órdenes posteriormente.
Tenga en cuenta que si su diseño de datos inicial y normalizado cumple con las necesidades de rendimiento de su aplicación, entonces está bien tal como está.
Se debe recurrir a la desnormalización solo cuando las pruebas de rendimiento muestren que tiene un problema con sus objetos y los perfiles posteriores revelan que debe mejorar el tiempo de acceso a la base de datos.
Modelado evolutivo / ágil de datos
El modelado evolutivo de datos es un modelo de datos realizado de forma iterativa e incremental. El modelado ágil de datos es un modelo evolutivo de datos hecho de manera colaborativa.
Aunque no lo piense, el modelado de datos puede ser una de las tareas más desafiantes con las que un administrador ágil puede involucrarse en un proyecto de desarrollo de software ágil.
Su enfoque del modelado de datos a menudo será el centro de cualquier controversia entre los desarrolladores ágiles de software y los profesionales de datos tradicionales dentro de su organización.
Los desarrolladores de software ágil se inclinarán hacia un enfoque evolutivo donde el modelado de datos es solo una de muchas actividades, mientras que los profesionales de datos tradicionales a menudo se inclinarán por un enfoque de diseño grande donde los modelos de datos son los artefactos primarios.
Este problema es el resultado de una combinación del desequilibrio de la impedancia cultural, una necesidad equivocada de aplicar la "única verdad" y maniobras políticas "normales" dentro de su organización.
Como resultado, los administradores ágiles a menudo descubren que navegar las aguas políticas es una parte importante de sus esfuerzos de modelado de datos.